
티스토리 뷰
저는 8월 12일 부로 협업툴 B2B 서비스를 운영하는 회사에 근무하게 되었습니다.
근황에 대해 짧게 이야기 하자면, 2주간의 온보딩을 마치고 과제를 받아 진행중입니다.
✔️ Overview
저는 개발을 학습해 오면서 널리쓰이는 DBMS인 MySQL을 주로 사용/학습을 진행 해 왔습니다.
제 회사에서는 단일 DB로 PostgreSQL을 사용하는데, 이때 까지 학습한 RDBMS인 MySQL과의 차이점에 대해 기술해 보고자 합니다! :)
[차이점 1️⃣] INDEX
🐬 MySQL
MySQL은 primary index를 테이블 당 반드시 하나 존재합니다. (지정 하지 않으면 MySQL InnoDB 스토리지 엔진이 자동 생성합니다)
primary key를 기준으로 primary index가 생성되며, 이는 clusered index라는 중요한 특징을 가집니다.
clustered index란 PK를 기준으로 물리적으로 디스크에 정렬되어 저장되게 됩니다.

따라서 세컨더리 인덱스(primary index를 제외한 모든 인덱스)를 통해서 데이터를 조회하게 된다면,
세컨더리 인덱스 B-Tree 구조의 leaf 노드에는 pk를 가지게 되고 pk로 primary index를 추가적으로 조회하여 디스크의 페이지에 접근하게 됩니다.
세컨더리 인덱스가 아닌 primary index를 통해 값을 조회하면 키가 존재하는 페이지와 해당 키 값인 전체 행을 찾을 수 있어서 추가적인 열을 가져오기 위해서 추가적인 IO가 발생하지 않습니다.
🐘 PostgreSQL
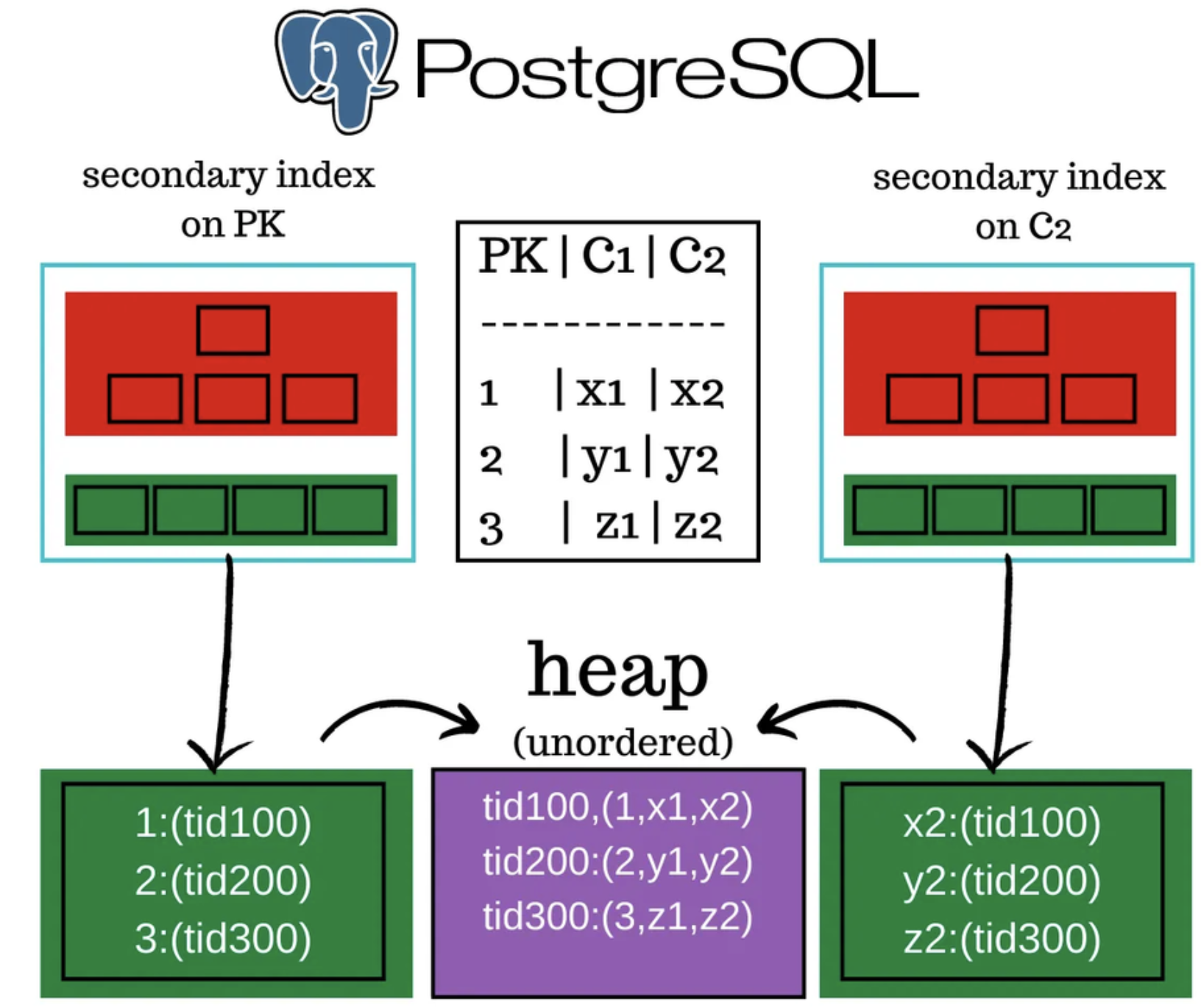
MySQL과 다르게 PostgreSQL에서는 primary index가 존재하지 않습니다.
또한, 모든 인덱스는 세컨더리 인덱스입니다. 또한 모든 인덱스는 heap 영역에 로드 된 데이터 페이지에 있는 tuple ID를 가리킵니다.
- tuple id(TID)는 두 부분으로 구성된 6byte 숫자입니다.
- 첫 번째 부분은 4byte 페이지 번호, 나머지 2byte는 페이지 내 튜플 인덱스입니다.
- 위 두 숫자의 조합으로 특정 튜플의 저장 위치를 고유하게 가리킵니다.

heap에 있는 테이블 데이터는 mysql의 primary index의 leaf page와 다르게 정렬되어 있지 않습니다.
- Heap은 테이블의 전체 행을 저장하는 저장 영역을 의미합니다.
- 여러 페이지로 나뉘며 기본적으로 8KB이며 각 항목 포인터는 페이지 내의 데이터를 가리킵니다.
PostgreSQL 테이블은 index origanized table이 아닌 heap organized table (힙 조직형 테이블)입니다.
또한 중요한 점이, postgreSQL에서는 update와 delete가 실제로는 insert입니다.
매 새로운 update와 delete가 발생할 때마다 새로운 tuple id가 생성되고, 이전 tuple id는 MVCC때문에 유지됩니다.
[차이점 2️⃣] MVCC를 보장하는 방법
MVCC는 multi version concurrency control이라는 뜻으로, transaction isolation level과 관련되어 트랜잭션간 데이터의 정합성을 맞춰주는 역할을 합니다.
🐬 MySQL
MySQL 8 버전 부터 default 스토리지 엔진으로 채택 된 InnoDB 스토리지 엔진은 레코드 수준까지 트랜잭션 제어를 제공해 줍니다.
이는 Isolation level에 따라 다른데, default로 REPEATABLE-READ로 설정되어 있습니다.
MVCC를 사용하는 이유는 락을 사용하지 않기 위해서인데, 동시성 제어를 위해서 락을 사용하면 가장 쉽지만 동시 요청시 성능이 떨어지기에 MVCC를 사용합니다.
❓어떻게 MVCC를 보장하는가
MVCC를 MySQL에서 보장하는 방법은 Undo Log(언두로그)를 활용합니다. 언두로그란 트랜잭션 격리 수준을 보장하기 위해 백업해 둔 변경 전의 데이터를 말합니다.
MySQL에서는 트랜잭션이 완료되지 않는다면 언두로그가 계속 쌓이기 때문에 트랜잭션을 가능한 짧게 유지해 언두로그가 쌓이지 않게 하는 것이 중요합니다.
언두로그는 InnoDB 스토리지 엔진에서 자동으로 삭제시킵니다. (Purge라는 과정인데, InnoDB의 백그라운드 스레드가 주기적으로, 자동으로 실행되어 사용자 개입의 필요성이 없습니다)
🐘 PostgreSQL
PostgreSQL은 MVCC를 위해서 update와 delete시 기존 데이터를 변경/삭제 하는것이 아닌 insert 작업이 일어납니다.
트랜잭션 격리 레벨의 default는 READ-COMMITTED입니다.
동시성 제어에 성능상 복잡한 것에 대해 MySQL보다 성능이 뛰어납니다.
하지만 update / delete 작업이 많이 발생하여 쌓이는 데이터 제거를 위해서 Vacuum이라는 clean up 작업이 필요합니다. (수동의 작업 필요)
🌪️ Vacuum VS Full Vacuum
- Vacuum에 일반 베큠과 풀 베큠이라는 두가지 종류가 있습니다.
일반 베큠
- 데드 튜플이 재사용가능하다고 마킹해 둬 용량은 그대로라 성능상 이점 얻기는 어렵습니다.
- 이후 새로운 업데이트가 이루어진다면 그 데드튜플을 재사용 합니다.
- 하지만 업데이트 잦지 않다면 일반 배큠으로 커버 가능합니다.
풀 베큠
- 데드 튜플들 모두 정리(삭제) 합니다.
- 바로 용량 확보하고 인덱스 팽창을 해결 합니다.
- Full Vacuum 수행 시 테이블에 lock이 걸려 모든 트랜잭션이 거부 됩니다.
하지만 문제는 운영 영향도로서 확실한 청소 방법이지만 24시간 운영된다면 고려할 사항이 많습니다.
Auto Vacuum
- 자동으로, 정기적으로 vacuum을 수행합니다. (lock 발생 x)
- 일반 베큠 + 통계를 갱신하기에 영향도를 잘 따져 설정해야 합니다.
[차이점 3️⃣] Thread 기반 vs Process 기반
🐬 MySQL
- 스레드 기반입니다.
- thread 간 컨텍스트 스위칭 시 TCB를 안전하게 공유 가능하지만 PC, Stack Pointer, Register는 업데이트 시켜주어야 합니다.
🐘 PostgreSQL
- 프로세스 기반입니다.
- 따라서 가상 메모리 오버헤드 + PCB가 TCB에 비해 커서 메모리를 많이 잡아 먹습니다.
- 컨텍스트 스위칭 시에도 프로세스간 컨텍스트 스위칭시에는 TLB를 무효화 시켜주는 작업이 필요합니다.
- 각 프로세스는 독립된 가상 메모리를 가지기에 하나의 프로세스가 죽더라도 다른 프로세스에 영향을 미치지 않습니다.
개인적인 추측, 어떤 RDBMS를 선택해야 할까?
⇒ 메모리 공유에 있어서는 thread 기반 RDBMS가 더 효율적일 것이라 판단됩니다. 하지만 안정성에 있어서는 PostgreSQL이 더 우위에 있을것이라 예상됩니다.
Reference
https://medium.com/@hnasr/postgres-vs-mysql-5fa3c588a94e
(위 블로그를 정리한 개인 노션 페이지 입니다)
MySQL vs PostgreSQL | Notion
간단하게 두 데이터베이스의 주요 차이점은
kaput-trombone-343.notion.site
'Programming > Database' 카테고리의 다른 글
| 🔐 동시성 문제 해결을 위해 어떤 Lock을 사용해야 할 까? - (2) DB Lock의 Shared Lock, Exclusive Lock Deep Dive 🔓 (2) | 2024.03.02 |
|---|---|
| 🔐 동시성 문제 해결을 위해 어떤 Lock을 사용해야 할 까? - (1) DB Lock에는 무엇이 있을까? 🔓 (0) | 2024.03.02 |
| 📻 SQL 성능 튜닝 - (2) 실행계획을 분석해 성능 튜닝을 해보자! (1) | 2024.01.31 |
| 📻 SQL 성능 튜닝 - (1) 왜 SQL 튜닝을 해야하지? 어떻게 하지? (1) | 2024.01.31 |
| 🤔 Repository 테스트시 auto_increment의 id 컬럼 의존성을 끊을수는 없을까? (2) | 2024.01.30 |
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday